Kafka实战指引 驾驭实时海量流式数据处理
在当今数据驱动的时代,实时处理海量数据流已成为企业构建敏捷业务、实现即时决策的核心能力。Apache Kafka,作为一个高吞吐、可水平扩展的分布式流处理平台,正是在这一背景下脱颖而出的关键技术。本文将提供一份实战指引,帮助您理解并运用Kafka进行高效的实时数据处理。
一、 Kafka核心概念与架构
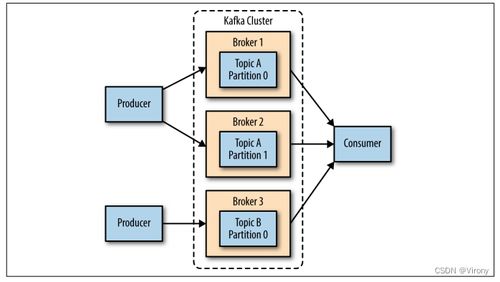
要驾驭Kafka,首先需理解其核心模型。Kafka以“主题”(Topic)为数据分类单位,生产者(Producer)将消息发布到特定主题,消费者(Consumer)则订阅这些主题以拉取消息。数据持久化在分布式、分区的“日志”(Log)中,确保了消息的顺序性和可重播性。其集群由多个代理(Broker)组成,通过ZooKeeper(或Kraft模式下的自管理元数据)进行协调,共同保障高可用性与容错性。这种简洁而强大的架构,正是其支撑海量数据流的基石。
二、 实战:构建实时数据处理流水线
- 数据采集与注入:利用Kafka Connect或自定义Producer,轻松集成数据库变更日志、应用日志、IoT设备数据、用户行为事件等多种数据源,将数据作为流实时注入Kafka主题。
- 流式处理与转换:这是数据处理的核心环节。可以借助Kafka原生的Streams API或与Flink、Spark Streaming等流处理框架集成。在此阶段,您可以进行丰富的数据操作:
- 过滤与清洗:剔除无效或噪声数据。
- 转换与丰富:将数据格式标准化,或通过查找外部数据源(如维表)补充上下文信息。
- 聚合与窗口计算:例如,计算每分钟的网站点击量、每小时的交易总额或滑动窗口内的用户活跃度。这些实时聚合结果本身又可作为新的数据流发布到Kafka。
- 数据分发与下沉:处理后的结果流,可以通过消费者应用程序实时推送到仪表盘进行可视化告警,或通过Kafka Connect的Sink连接器写入下游系统,如数据仓库(ClickHouse、Hive)、搜索引擎(Elasticsearch)、缓存(Redis)或其它数据库,供进一步分析与服务调用。
三、 处理海量数据的关键实战技巧
- 性能调优:根据实际负载调整生产者的批量提交大小、压缩算法,消费者的拉取批次大小与间隔。合理设置主题的分区数,以并行度换取吞吐量。
- 容错与 Exactly-Once 语义:合理配置生产者确认机制(acks)和消费者的偏移量提交策略。利用Kafka Streams或集成框架的事务支持,在流处理中实现端到端的精确一次处理,确保计算结果在故障恢复后不重不丢。
- 监控与运维:密切监控集群健康度(Broker负载、网络IO、磁盘使用)、主题流量(消息进出速率、积压量)以及消费者组的滞后情况。利用Kafka自带的指标和外部监控系统(如Prometheus)构建仪表盘,以便快速发现瓶颈与异常。
- 资源规划与安全:根据数据吞吐量和保留策略规划存储容量。在生产环境中,务必配置SSL/TLS加密、SASL认证和基于ACL的授权,保障数据安全。
四、 典型应用场景
Kafka的实时数据处理能力在众多场景中大放异彩:实时推荐系统依据用户即时行为更新推荐结果;金融风控系统对每笔交易进行毫秒级欺诈检测;物联网平台处理亿万设备上报的传感器数据并触发实时告警;企业级数据中台构建统一、高效的实时数据管道。
掌握Kafka实战,意味着您拥有了构建低延迟、高可靠实时数据系统的强大工具。从理解其核心原理出发,通过精心设计的数据流水线,结合性能调优与稳健的运维实践,您将能从容应对海量流式数据的挑战,释放实时数据的巨大业务价值。记住,成功的实时处理系统始于一个稳定、高效的数据流中枢,而Kafka正是这一角色的卓越担当。
如若转载,请注明出处:http://www.huaxiasjw.com/product/11.html
更新时间:2026-06-18 14:16:52