初识Hadoop 大数据处理的基石
什么是Hadoop?
Hadoop是一个开源框架,由Apache基金会开发,用于在分布式计算环境中存储和处理大规模数据集。其核心理念来源于Google的MapReduce和Google文件系统(GFS)论文。Hadoop旨在从单一服务器扩展到数千台机器,每台机器都提供本地计算和存储,从而构建一个高可靠、高扩展性的系统。
Hadoop的核心组件
Hadoop生态系统主要包含两大核心组件:
- Hadoop分布式文件系统(HDFS)
- 设计目标:存储超大数据集,并提供高吞吐量的数据访问。
- 工作原理:它将大文件分割成多个数据块(通常为128MB或256MB),并将这些数据块冗余地存储在多台机器上,默认副本数为3。这种设计确保了数据的可靠性和可用性。
- 主要角色:
- NameNode:主节点,负责管理文件系统的命名空间(如目录树、文件元数据)以及数据块的映射信息。它是整个系统的“大脑”。
- DataNode:从节点,负责存储实际的数据块,并响应NameNode和客户端的读写请求。
- Hadoop MapReduce
- 设计目标:对存储在HDFS上的大规模数据进行并行计算。
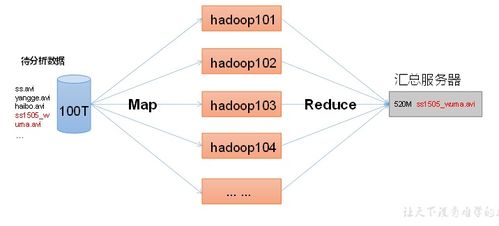
- 编程模型:采用“分而治之”的思想,将计算任务分为两个主要阶段:
- Map阶段:将输入数据拆分成独立的片段,由多个Map任务并行处理,输出一系列的中间键值对。
- Reduce阶段:将Map阶段输出的、具有相同键的中间结果进行汇总和整理,生成最终的输出结果。
- 执行框架:它负责任务调度、监控以及失败任务的重新执行,将程序员从复杂的分布式编程细节中解放出来。
Hadoop如何助力大数据处理?
- 处理海量数据:Hadoop能够轻松处理PB甚至EB级别的数据,这是传统关系型数据库难以企及的。
- 成本效益:它被设计运行在由廉价商用硬件组成的集群上,通过软件层面的容错机制来保障可靠性,大大降低了硬件成本。
- 高扩展性:通过简单地增加集群节点,即可线性地扩展系统的存储能力和计算能力。
- 高容错性:数据在HDFS上被多副本存储,计算任务在失败时会被自动重新调度到其他节点执行,确保了作业的顺利完成。
- 适合批处理:MapReduce模型非常适合对海量历史数据进行离线、复杂的批量分析和计算,如日志分析、数据挖掘、推荐系统等。
Hadoop生态系统的扩展
随着技术的发展,围绕Hadoop核心形成了一个庞大且活跃的生态系统,引入了更高效、更易用的工具,例如:
- YARN:作为Hadoop 2.0引入的资源管理框架,它将资源管理与作业调度/监控分离开来,使得Hadoop可以运行除MapReduce之外的其他计算框架(如Spark、Flink)。
- Hive:提供类似SQL的查询语言(HiveQL),将复杂的MapReduce程序简化为熟悉的查询语句,降低了大数据分析的门槛。
- HBase:一个构建在HDFS之上的分布式、面向列的NoSQL数据库,支持实时读写和随机访问。
- Spark:一个基于内存计算的快速、通用的大数据处理引擎,常与Hadoop的存储系统(HDFS)结合使用,提供了比MapReduce更快的处理速度。
##
Hadoop作为大数据技术的开拓者和基石,通过其分布式存储(HDFS)和分布式计算(MapReduce)模型,首次为业界提供了一套经济、可靠、可扩展的处理海量数据的解决方案。尽管其原生的MapReduce引擎在实时性上存在局限,但其思想和架构深刻影响了后续所有大数据技术的发展。理解Hadoop是进入大数据领域的重要第一步,其生态系统中的众多工具共同构成了现代企业大数据平台的核心。
如若转载,请注明出处:http://www.huaxiasjw.com/product/18.html
更新时间:2026-06-18 07:54:49